高機能エディタの使い方
データセットd中の4つの項目から構成される尺度の信頼性の検討と尺度得点の算出を想定してください。本書に記載した方法に従うと、
- 尺度を構成する4つの項目だけを集めたデータフレームを作成
- 作成したデータフレームを信頼性係数を算出する関数の引数に指定して実行
- 4つの項目を用いて尺度得点を算出
という順番になります。以下がスクリプトです。
【スクリプト】
- 尺度を構成する4つの項目だけを集めたデータフレームを作成
scale <- d[c("a01", "a02", "a03", "a04")]
- 作成したデータフレームを信頼性係数を算出する関数の引数に指定して実行
omega (scale)
- 4つの項目を用いて尺度得点を算出
d$scale_score <- (d$a01 + d$a02 + d$a03 + d$a04)/4
スクリプトの赤字部分に注目すると、項目部分が共通しています。律儀にダブルコーテーション(” “)とカンマ(,)を削除してプラス(+)を足してもいいのですが、項目数が多い場合や尺度数が多い場合は非常に面倒です。また、ミスの増加にもつながります。
このような場合に便利なのが正規表現です。正規表現とは、複数の文字列をひとつの集合として表現する方法のことです。上記の例の場合、ダブルコーテーション、カンマ、ダブルコーテーション(”, “)を集合とし、それをプラス(+)に置換することで作業が簡単になります。そこで、高機能エディタを用いて正規表現を実行します。
正規表現が使える高機能エディタとしては、以下のようなものが挙げられます。
【Windowsを使用している場合】
- サクラエディタ(無料)
- TeraPad(無料)
- 秀丸エディタ(有料)
- EmEditor(有料)
【Macintoshを使用している場合】
- CotEditor(無料)
- mi(無料)
軽量な無料ソフトから,非常に高機能な有料ソフトまで様々なものがあります。このページでは,Windows上でTeraPadを用いて進めていきます。他のソフトを使用した場合でも基本的な考え方は同じなので、各ソフトのマニュアルを読んで進めてみてください。
■尺度得点
では、TeraPadを起動してください。起動して、“a01”, “a02”, “a03”, “a04″を貼り付けると次図のようになります。
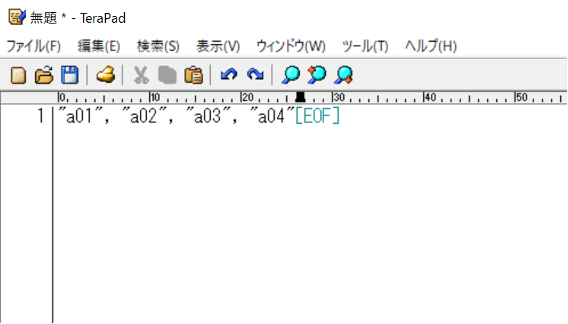
次に、検索タブから置換を選択してクリックします。「検索する文字列」に”, “を、「置換後の文字列」に + を入力し、「すべて置換」をクリックします。
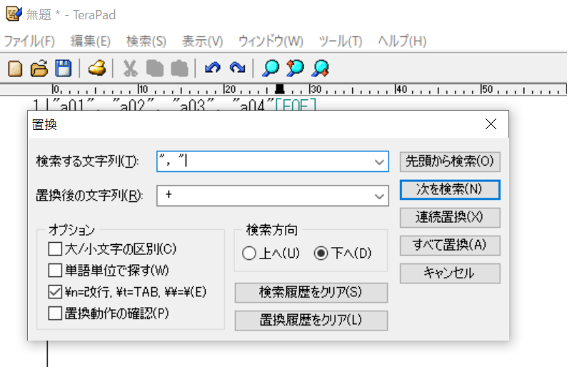
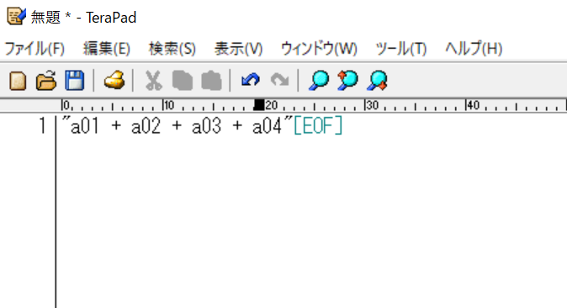
すると、次図のように”, ”を + に置換することができます。ここで注意点が2つほどあります。1つ目は始めと最後のダブルコーテーションとカンマについてです。今回は”, “をひとつの集合として + に置換したため、ダブルコーテーション単体は置換の対象外となります。そのため、データフレームに入れる形にするためには、最初の項目の前のダブルコーテーションを削除する必要があります。また、最後の項目の後も”, “となっており、カンマとダブルコーテーションを削除する必要があります。
2つ目は、半角スペースです。テキストエディタは半角スペースも認識するので、置換対象の文字列に半角スペースが含まれている場合は、「検索する文字列」にも半角スペースを含める必要があります。今回の場合だと、カンマの後に半角スペースがあります。また、置換後+の前後に半角スペースを入れたい場合は、「置換後の文字列」には半角スペース、プラス(+)、半角スペースと入力する必要があります。
■因子分析
本書の第5章や第9章で扱っている探索的因子分析では、因子構造を単純構造に近づけるために、因子パタン値が小さい項目や複数の因子が負荷している項目を削除しています。そして、削除後の項目だけを入れたデータフレームを新たに作成し、そのデータフレームを用いて再び因子分析や信頼性の検討を繰り返します。
手数が少ない場合や項目数が少ない場合は手動で項目を削除しても大丈夫でしょう。しかし、手数が多い場合や項目数が多い場合はミスが発生しやすくなります。そこで、正規表現が使える高機能エディタとExcelを組み合わせることで、効率的に因子を探索する方法を紹介します。ただし、因子の探索は数値のみを基準に機械的にするのではなく、解釈可能性も考慮してください。
はじめに、因子分析の結果をExcelに貼り付けます。今回は、第5章のデータを用いています。因子分析結果から分かるように、3因子を想定しています。因子分析の結果をExcelに貼り付ける方法については、本書のp190およびサポートページを参照してください。
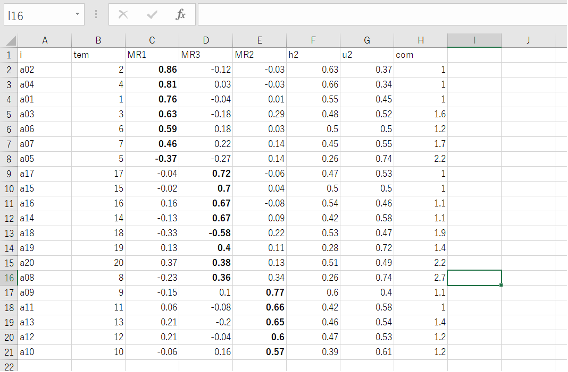
次に、削除したい項目の右横の列(図では〜列)に×(バツ)を入れます。今回は×を入れましたが、任意の記号でかまいません。削除候補の項目に×を入れたら、Excelのフィルター機能を利用します。ホームタブの「並べ替えとフィルター」もしくはデータタブの「フィルター」をクリックしたら、×の左横のチェックを外してOKをクリックします。
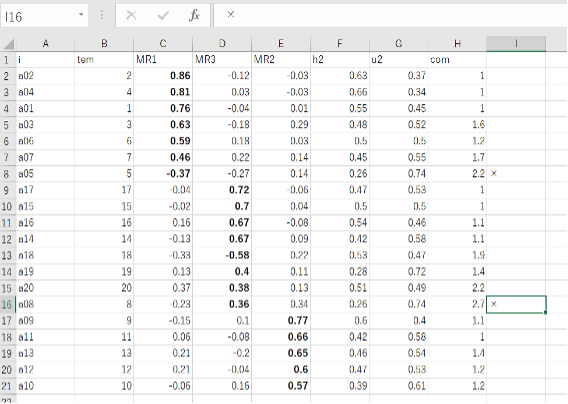
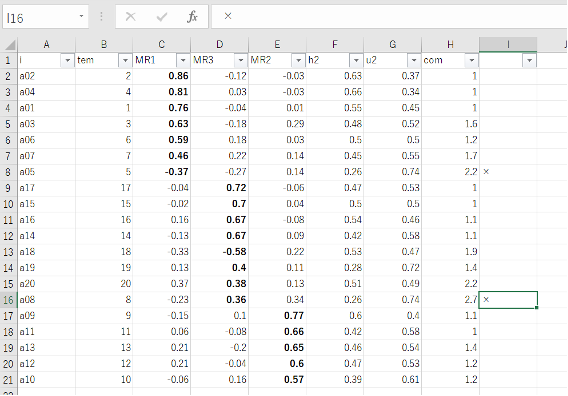
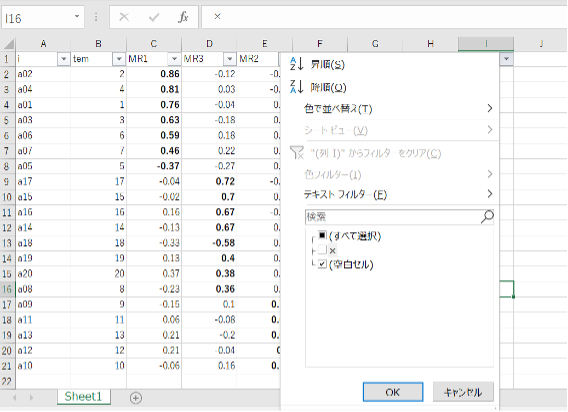
すると、次図のように×を記入した項目以外の項目が表示されるので、表示された項目を全てコピーします。
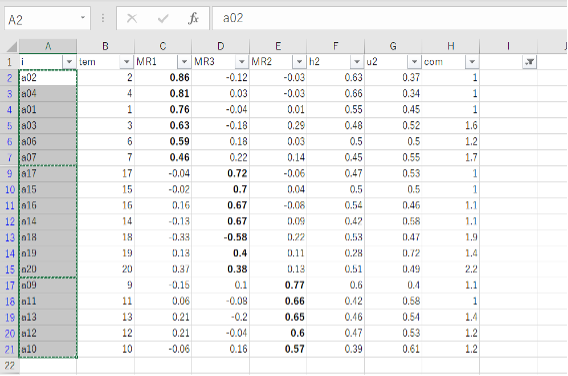
キストエディタ(今回はTeraPad)を起動し、先ほどコピーした項目番号を貼り付けます。
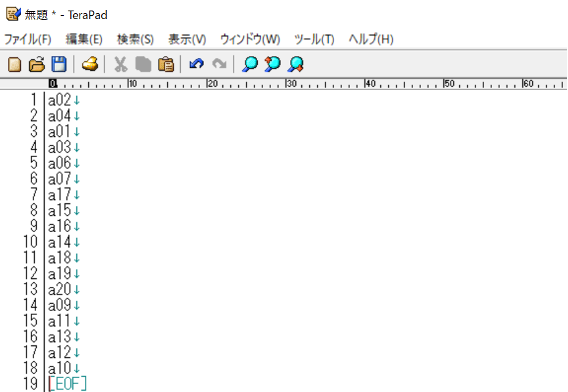
ここで項目番号の横にある↓に注目してください。↓は、「改行」を意味する記号です。この↓を”, “(ダブルコーテーション、カンマ、ダブルコーテーション)に置換することで、ダブルコーテーションで挟んだ項目番号を横一列に並べることが可能です。例えば、
a01↓
a02↓
a03↓
は、
a01", "a02", "a03”,”
に置換されます(赤字部分)。ただし,このままだと最初の項目の前はダブルコーテーションが抜けている、また、最後の項目の後はカンマとダブルコーテーションが余分となっており、データフレームに入れる形になっていないことに注意してください。そこで,最初の項目の前にダブルコーテーションをつけ,最後の項目の後のカンマとダブルコーテーションを削除すれば,
"a01", "a02", "a03"
となり、無事、データフレームに入れることが可能な形になります。
では、実際に実行してみます。尺度得点のときと同様に、検索タブから置換を選択してクリックしてください。今回は、「検索する文字列」に\n、「置換後の文字列」に”, “を入力します。
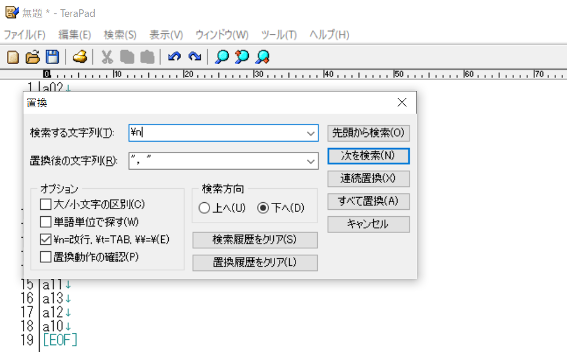
半角スペースの不備等がないことを確認できたら「すべて置換」をクリックします。すると、次図のようになります。図上では右側が見切れていますが、実際は全ての項目が表示されています。
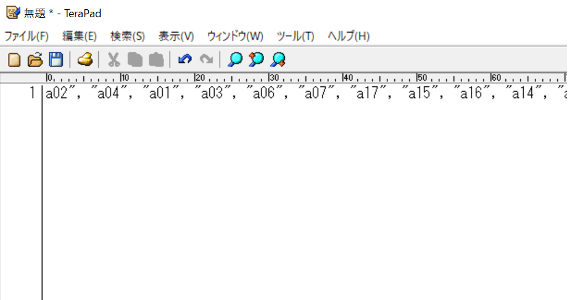
置換が成功しているのを確認できたら、最初の項目の前と最後の項目の後を確認しましょう。最後の項目の後については、これまでと同様に、カンマとダブルコーテーションが余分なので削除します。ただし、最初の項目の前については、これまでと違ってダブルコーテーションが足りません。そのため、データフレームに入れる形にするためには、ダブルコーテーションを1つ足します。
Copyright © Wakita Takafumi.